Recent improvements
What is DBI?
The DBI package (database interface) is a layer between R and database management systems (DBMSes). Users who interact with DBMSes via the DBI package are able to use the same API for all DBMSes. Implementations of this API are provided by DBMS-specific backend packages, such as RPostgres, RMariaDB, and RSQLite. If you are new to DBI, you can find a good entry point in the introductory tutorial.
The interface is designed to be simple and consistent, making it easy to switch between different DBMSes. Packages built on top of DBI, such as dbplyr or arkdb, provide additional functionality and convenience. New backends can be implemented by following the DBI specification, which comes with a comprehensive test suite in the DBItest package. The RKazam template makes it easy to get started. (Spoiler alert: We know because a new backend has been added recently. Read on!)
This blog post series consists of three parts. In this first part, we summarize recent developments in DBI and related packages, including a glimpse on the new adbi package. The second part reviews the time it takes to respond to issues and pull requests. In the third part, we will do a deeper dive into the new adbi and adbcdrivermanager packages, which use the Arrow data exchange format and offer a more sustainable approach to database connectivity.
Similar articles are available from previous years, reporting on earlier states of the DBI ecosystem:
Overall
Improve CI/CD infrastructure
Packages run their own checks and the checks for related components. For example, DBI now runs DBItest with RSQLite, and DBItest runs checks for all backends, including odbc. This ensures interoperability between CRAN and development versions of the packages and helps to catch issues early.
Several components simplify the day-to-day work:
Aviator helps ensuring always “green” builds on the main branch.
It is a “click-and-forget” solution that allows queueing a pull request so that it is automatically merged when all checks pass. I’m using this for all my packages now, and it has saved me a lot of time. I also tried the native GitHub merge queue, but it seems to require protecting the main branch, which is required for fledge. 👇
fledge helps automating the release process.
This package generates a changelog from PR titles. In my setup, it is run daily and automatically updates
NEWS.md. Before release to CRAN, the changelog is manually converted to release notes. Once a package is on CRAN, a GitHub release is created with these release notes.All packages use a similar but not identical setup for CI/CD.
For example, the DBMS installed differs between backends. To manage this and also allow continuous improvement of the CI/CD process, I’m using bidirectional synchronization to and from a central repository. This allows me to make changes in one of the repositories and have them applied to all other repositories. Among other things, the improved CI/CD workflows automatically open pull requests for changes to autogenerated files such as
.Rdfiles or the results of snapshot tests.
Improve testing infrastructure
Testing DBI and associated packages often requires a database server. While it is easy enough to install MariaDB and PostgreSQL to run locally, running Oracle and SQL Server on macOS requires Docker. If some databases require Docker, why not run all databases in Docker? This gives the additional advantage of being able to install different versions of the same database server side by side, and to easily recreate a fresh test environment.
The docker repository aims at providing a consistent and easy-to-use setup for all databases and all packages. It uses Docker Compose to turn otherwise complex command line invocations into a single docker-compose command. The goals are:
Have a single robust command to create a server and a test connection, testable with CI/CD.
Offer an easy way to run tests or scripts against a particular database server, using a development version of a backend package.
Support testing all useful combinations of DBI backend and database server.
Make it easy to add new database versions, new databases, and new backends.
The repository is still in its early stages, but it already supports MariaDB, MySQL, PostgreSQL, SQLite, SQL Server, and Oracle. Feedback and contributions are welcome.
Documentation improvements
Various documentation improvements have been made:
The DBI specification is now version-controlled as Markdown files. This allows for more control and a simpler build process. Previously has been assembled at package build time from various sources.
The command execution and data retrieval flow has been clarified in the documentation. This has been a common source of confusion for new users.
All packages now use the new pkgdown documentation template at https://github.com/r-dbi/dbitemplate, and the website at https://r-dbi.org is now built using Quarto. Thanks to Maëlle Salmon (@maelle)!
Move to cpp11
The RSQLite, RPostgres, and RMariaDB packages are now using the cpp11 package for the glue between R and C++. This header-only package provides a modern C++11 interface to R, the header files can be vendored into the backend packages if needed. Other highlights include the use “UTF-8 everywhere” paradigm, improved safety of C API calls, and a faster implementation of protection.
Avoid tidying of duplicate column names
The RSQLite, RPostgres, and RMariaDB packages no longer change duplicate column names. The behavior in the presence of duplicate column names was not specified in the DBI specification, but imposing a tidying step seems out of scope for a database interface. It is now up to the user to handle duplicate column names, for example by using janitor::clean_names().
adbi: new release in collaboration with Voltron Data
The new adbi package bridges ADBC drivers and DBI. Examples include:
- adbcsqlite, on CRAN
- adbcpostgresql, on CRAN
- adbcsnowflake for Snowflake
- adbcflightsql for FlightSQL
- duckdb, which implements an ADBC driver in addition to the DBI backend
ADBC (Arrow database connectivity) is
an API standard for database access libraries that uses Arrow for result sets and query parameters.
The adbi package allows existing code that uses DBI to seamlessly interact with the new ADBC drivers, but this will not improve performance. To facilitate the switch to using Arrow as a data interchange format, adbi supports access via data frames and Arrow side by side, on the same connection object, using the new generics defined by DBI. For example, with dbGetQueryArrow(), the result set is passed to R as an Arrow stream, bypassing the expensive conversion to data frames. More on that below.
Development of the adbi package has been made easy with the RKazam package, which is a template for creating DBI backends, and the DBItest package, which provides a battery of tests that all “pass” with the package generated from the template and help guide the development process. Thanks to Nicolas Bennett (@nbenn) for the implementation and the wonderful collaboration, and to Voltron Data for supporting this effort.
DBI
This package has seen a minor update to 1.2.2. See the change log for the full details.
Integration with Arrow
DBI backens can now optionally support Arrow arrays and streams as the primary data exchange format. This is accessed through the new generics dbSendQueryArrow(), dbFetchArrow(), dbFetchArrowChunk(), dbGetQueryArrow(), dbReadTableArrow(), dbWriteTableArrow(), dbCreateTableArrow(), dbAppendTableArrow(), and dbBindArrow(). See the new vignette on Arrow support in DBI for details.
A default implementation is provided in the DBI package, this means that the new interface can be used with any DBI backend without changes to the backend package. Performance and interoperability gains can be achieved by directly implementing the Arrow interface in the backend package, as the new adbi package does.
The following example illustrates two options to connect with a PostgreSQL database. In both scenarios, the libpq library is used to communicate with the database server. The RPostgres package links to libpq, the PostgreSQL client library, and uses this API directly to retrieve and ingest data from R via the DBI interface. The adbcpostgresql package also links to libpq but exposes ADBC, which is brought to R with the adbcdrivermanager package. On top of that, the adbi package interacts with arbitrary ADBC drivers (including adbcpostgresql) and exposes the functionality through DBI. The R user has the choice to access the data via data frames or via Arrow. When using adbi and the new dbGetQueryArrow(), the implementation will never convert the data to R data frames. This allows, e.g., directly saving the result to a Parquet file, or further processing it with Arrow. In all other cases, a conversion to R data frames will occur.
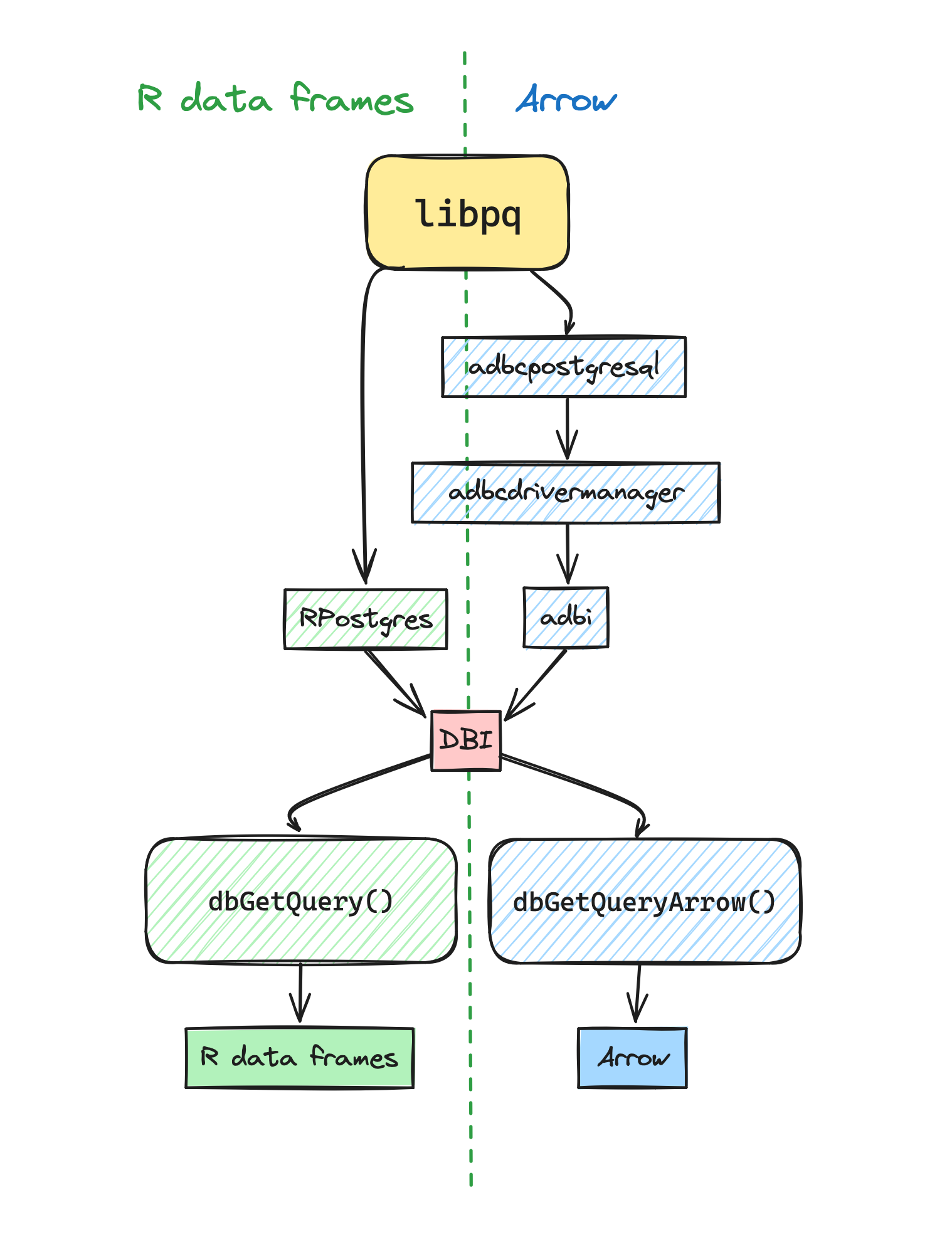
While the Arrow path seems to involve more components, it is the most efficient way to interact with the database because the data is threaded through from adbcpostgresql to R without any conversion or even copying. The only conversion occurs in adbcpostgresql, when the data returned by libpq is converted to Arrow format.
With FlightSQL, the data will be passed in the Arrow format end to end, this requires support in the database server. This is a promising development. By using adbi or adbcdrivermanager, R users can seamlessly transition to FlightSQL when it becomes available in their database.
Thanks to Voltron Data for supporting this effort!
Object identifiers
The Id() class has been changed to unnamed components, as the explicit naming of the components (“database”, “schema”, “table”) was not used in practice. This also affects the dbQuoteIdentifier(), dbUnquoteIdentifier(), and dbListObjects() generics, which now accept and return unnamed Id() objects.
DBItest
The DBItest package has seen a minor update to 1.8.1. See the change log for details.
Code generation
Why good developers write bad unit tests? In a nutshell, production code should avoid repetition and hard-coded constant, while testing code should be as explicit and as easy to understand and execute as possible.
The DBItest package is home to both the specification of the DBI package and a test suite for DBI backends. As such, good software engineering practices are actually useful here and have helped cover many corner cases in the DBI backends. Running the tests in DBItest is easy, but in the case of a failure, the error messages are not always helpful. Backend developers typically have to read the test code to understand what went wrong. And if the actual test code hides between layers of abstraction, this can be a daunting task.
Code generation has proved to be a powerful tool to peel off abstraction layers, for instance in the duckplyr project. In R, code is data, and the language and the associated packages are very well suited for this task. The long-term goal is to turn DBItest into a code generator rather than a test executor: the test code will be generated from a specification directly into the backend package and executed there. In the case of a failure, the error message will point to the generated code and to the relevant part of the specification. Failing tests can be executed trivially, very much like failures in regular tests. The expected behavior becomes apparent from the generated code, leading to a better understanding of the failure and a more efficient debugging process.
A first step has been taken in this direction, the tests for the command execution and data retrieval flows via dbBind() have been refactored to generate inline code in the DBItest package. The process towards full code generation requires similar steps in a few other places to avoid hard-to-understand generated code, which would be even worse than the current situation.
Decoupling from backends
As DBItest continues to evolve, and more backends are using it, the ability to add or update checks without affecting all downstream packages becomes crucial. Each new or modified test will require the backend package to opt in by updating the DBItest version in their tweaks() call. Once the code generation is in place, this will become less of an issue, but for now this helps with the ongoing development.
Other improvements
The new Arrow generics are now tested in DBItest, and the tests have been integrated into the CI/CD pipeline.
A new tweak allow_na_rows_affected has been added to support NA values returned from dbGetRowsAffected() and passed as the n argument to dbFetch().
Backend packages: RSQLite, RMariaDB, RPostgres
RSQLite has seen a minor update, the current version is 2.3.6. See the change log for details.
The automatic update of the bundled SQLite library has enabled continuous and timely updates of the RSQLite package on CRAN. The latest version of SQLite is 3.45.2, and the RSQLite package is now bundling it. For this reason, the known authors of SQLite have been added to the
DESCRIPTIONfile. This process allows quicker updates of SQLite than if installing from OS package repositories, and precise control of the underlying SQLite version used in a project.Other minor changes include support for the icpc compiler, and a new
sqliteIsTransacting()function that returns if a transaction is active on the current connection.RMariaDB has also seen a minor update. The current version is 1.3.1. See the change log for details.
MariaDB is a fork of MySQL, and both packages continue to evolve. There are small but important differences between the two DBMSs, and the RMariaDB package is now more explicit about the differences. Connections now inherit from
"MySQLConnection"if a MySQL server is detected (server version < 10.0 and server description does not contain"MariaDB"). The newmysqlargument todbConnect()allows overriding the autodetection. This means that code can behave differently depending on the underlying database server.Similarly to RPostgres and odbc, RMariaDB now supports
dbSendStatement(immediate = TRUE)anddbExecute(immediate = TRUE). This sends the query to the server without preparing it, which is mandatory for some queries. For this to work, the connection needs to be opened with theCLIENT_MULTI_STATEMENTSflag.Other changes include:
Support for
TIMEcolumns with subsecond precision.The use of strings as default for JSON and all unknown column types.
RPostgres has seen a minor update, mostly focusing on maintenance. The current version is 1.4.6. See the change log for details.
Conclusion
Quite a few things have happened in the DBI ecosystem since the last blog post. Try out the new package versions, let us know if they work for you, and report any problems you encounter in the respective issue trackers on GitHub. Happy querying!
Acknowledgments
Thanks to Maëlle Salmon (@maelle) and Nicolas Bennett (@nbenn) for their help with the blog post, and to the numerous contributors to the packages in the “Maintaining DBI” project in 2022 and 2023:
DBI: @apalacio9502, @asadow, @bcorwin, @capitantyler, @chrisdane, @eauleaf, @eitsupi, @eriksquires, @fnavarro94, @GitHunter0, @hadley, @hannes101, @Jay123ub, @jd4ds, @kelseyroberts, @latot, @maelle, @matthiasgomolka, @mgirlich, @mmuurr, @nbenn, @philibe, @pnacht, @r2evans, @renkun-ken, @salim-b, @scottfrechette, and @tzakharko.
DBItest: @barracuda156, @detule, @dpprdan, @hadley, @maelle, @MichaelChirico, @nbenn, @psychelzh, and @TSchiefer.
RSQLite: @Antonov548, @arnaud-feldmann, @bpvgoncalves, @chodarq, @Daniel-Zhou-93, @DavorJ, @eriksquires, @gaospecial, @gavril0, @github-actions[bot], @hadley, @IdoBar, @JeremyPasco, @joethorley, @kjellpk, @kmishra9, @krlmlr, @lolow, @maelle, @MichaelChirico, @nathaneastwood, @nunotexbsd, @RoganGrant, @SarenT, @stephenashton-dhsc, @wibeasley, and @xmart.
RPostgres: @abalter, @ablack3, @agilly, @aliarsalankazmi, @ankane, @Antonov548, @bhogan-mitre, @castagninojose, @DavisVaughan, @dmkaplan2000, @dpprdan, @geneorama, @gui-salome, @ilarischeinin, @jeroen, @karawoo, @kevinpalm, @kmishra9, @maelle, @majazaloznik, @meztez, @mgirlich, @mmuurr, @nbenn, @pachadotdev, @pedrobtz, @samterfa, @sbamin, @stefan-m-lenz, and @veer0318.
RMariaDB: @Antonov548, @arecibo, @bergernetch, @BillWeld, @cboettig, @d-hansen, @EllyJung, @frabau1, @ghost, @GitHunter0, @GraphZal, @GundryLab, @hpages, @jay-sf, @jd4ds, @jeroen, @KevinYie, @kwakuduahc1, @lbui30, @LeeMendelowitz, @LukeBla, @maelle, @mbarneytu, @mgirlich, @MySocialPulse, @NoProblemJack, @pekkarr, @psychelzh, @pythiantech, @renkun-ken, @rorynolan, @ryan-hdez, @SwissMontainsBear, @uhkeller, and @vanhry.